ClickHouse 可视化构建
ClickHouse 可视化构建
近期公司将存储组件从 Elasticsearch 迁移至 ClickHouse,并且线上已经稳定运行一段时间了。鉴于当前运行稳定的状况,可以考虑逐步下线 Elasticsearch 集群以节省资源。然而,ClickHouse 目前缺乏像 Kibana 那样强大的可视化组件,这使得我们无法直接通过网页来观察和分析数据。因此,在完全下线 Elasticsearch 集群之前,我们需要为 ClickHouse 构建或集成一套新的可视化组件,以便能够直观地展示和分析日志数据。
方案选择
目前开源的方案有两种:ClickVisual 和 CKibana
https://clickvisual.net/
https://tongchengopensource.github.io/ckibana-docs/
ClickVisual 是一个轻量级的开源可视化平台,专注于为 ClickHouse 提供日志查询、分析和报警功能。作为目前市面上唯一一款支持 ClickHouse 的类 Kibana 业务日志查询平台,ClickVisual 提供了一种直观的方式来可视化 ClickHouse 中的数据。然而,需要注意的是,ClickVisual 的功能相对基础,主要提供直方图等简单的数据展示形式,并不支持创建复杂的仪表盘。
CKibana 是一个旨在原生 Kibana 上使用 Elasticsearch 语法查询 ClickHouse 的服务。它本质上是基于 Kibana,因此无法完全摆脱对 Elasticsearch 的依赖(需要将 Kibana 的元数据存储在 Elasticsearch 中),但它为用户提供了一个在熟悉的 Kibana 界面中查询 ClickHouse 数据的解决方案。
考虑到上述信息,我更倾向于选择 CKibana 作为可视化工具。CKibana 的优势在于它允许用户直接在熟悉的 Kibana 界面中使用 Elasticsearch 语法查询 ClickHouse,从而实现了从 Elasticsearch到 ClickHouse 的平滑切换。对于已经熟悉并喜欢 Kibana 的用户来说,这种方案不仅减少了学习新工具的成本,还保持了他们熟悉的工作流程,使得整体切换过程更加顺畅和高效。
方案介绍
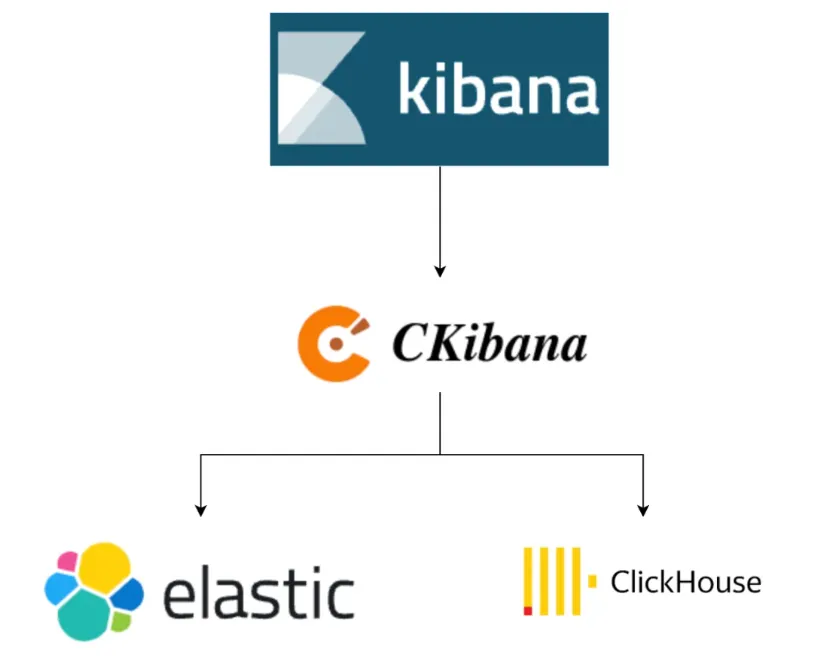
CKibana 通过在原生 Kibana 与 Elasticsearch 之间增加一层代理(Proxy),实现了 Elasticsearch 查询语法到 ClickHouse 的转换,如图:
搭建测试环境
组件介绍
- Kibana: 用来提供给业务做 UI 展示
- ElasticSearch: 用来做 kibana 元数据存储 + 查询缓存等高级特性
- ClickHouse: 真实存日志数据的存储
- CKibana: 提供 Proxy 等高级功能,实现让用户直接在原生 Kibana上查询 ClickHouse 数据
组件搭建
整个链路涉及四个组件(Kibana、Elasticsearch、CKibana 和 ClickHouse),直接安装并配置这些组件可能会遇到各种环境问题,如依赖冲突、版本不兼容等。为了简化安装和配置过程,使用 docker-compose 构建测试环境是一个高效且方便的选择。
1 | |
1 | |
注意事项
- Kibana 不再直接连接到 Elasticsearch,而是通过 CKibana 进行中转
- CKibana 的 metadata-config 中 headers 是必须被配置的,即使 Elasticsearch 不需要验证
- CKibana 依赖的 Elasticsearch 必须有集群信息
- CKibana 连接 ClickHouse 的 url 中不能存在 _ (个人踩坑)
- CKibana 连接 ClickHouse 必须有用户名和密码,不能为空(这个设计十分不合理)
实操一下
根据上述信息,执行 docker-compose up 命令来启动环境。如果在启动过程中遇到 CKibana 的报错提示,不必过分担心,这通常是因为 Elasticsearch 服务尚未完全初始化。只要最终四个组件都成功启动,就说明环境搭建没有问题。
给 ClickHouse 搞点数据
1 | |
CKibana 基本配置
建立 ClickHouse 连接
这里需要注意 CKibana 只能与一个 ClickHouse 集群建立连接,调用接口后会覆盖原有配置
1 | |
更新白名单索引
只有在白名单中的索引(即 ClickHouse 中的 table)才能在 Kibana 中查看数据, 调用接口后会覆盖原有配置 (建议保存一份线上数据)。如果想要查看名为 “demo” 和 “demo1” 两个表格的数据,则需要在调用的接口中,通过名为 “list” 的参数来指定这两个表格,并用逗号将它们分隔开。例如,参数的值应该是 “demo,demo1”。
1 | |
简单使用
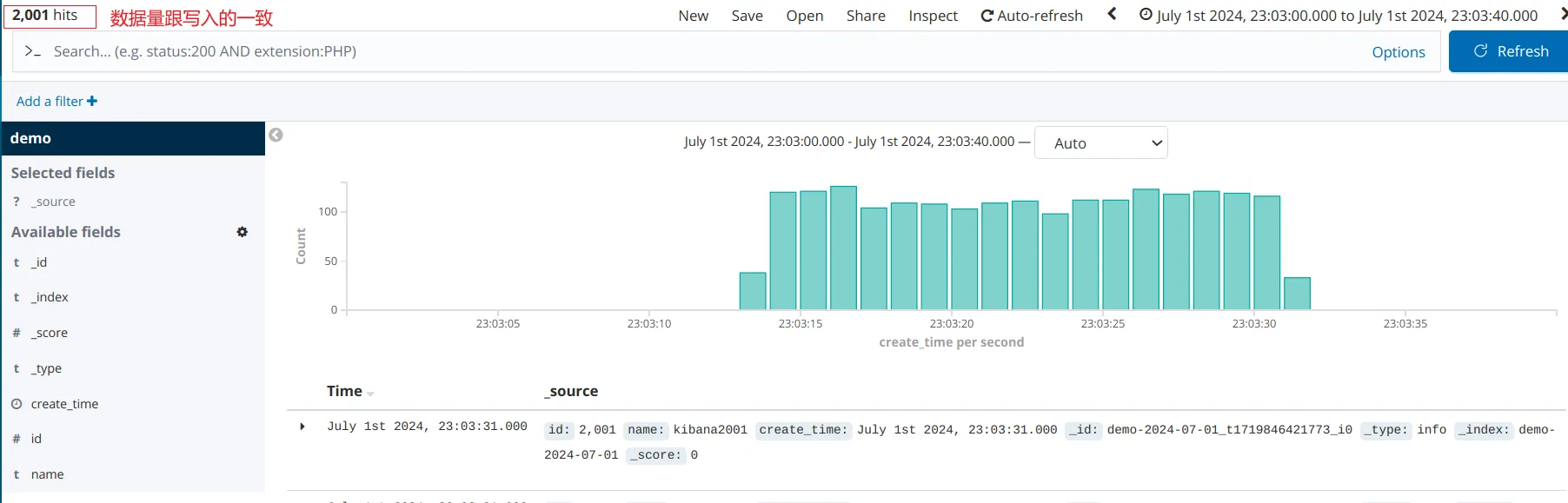
上面两个配置正确配置后,就可以在 kibana 中查看 ClickHouse 的数据了!!!
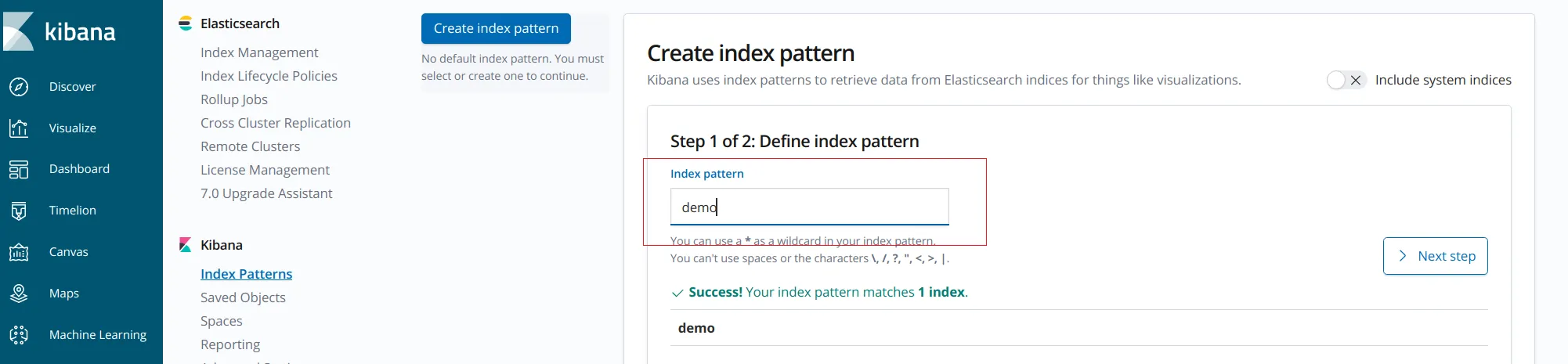
- index pattern 跟 ClickHouse 表名是精确匹配,不能使用通配符 *
- 注意时间字段,否则会筛选不了时间字段
- 字段为 Date 类型,比如 DateTime64 类型,会被认为是时间类型
- 字段名中包含 time,比如 timestamp UInt64,会被认为是时间类型
CKibana 其他配置
更新黑名单索引
黑名单列表,配置的索引不会走 ClickHouse 查询,而是直接查询 Elasticsearch 。
1 | |
更新 maxTimeRange(单位 ms)
很多时候,有人想要查看某个条件最近的趋势,直接查询最近 30 天等等,这样会导致资源消耗比较大,所以 CKibana 支持了最长时间查询范围,来限制使用。
1 | |
更新 enableMonitoring
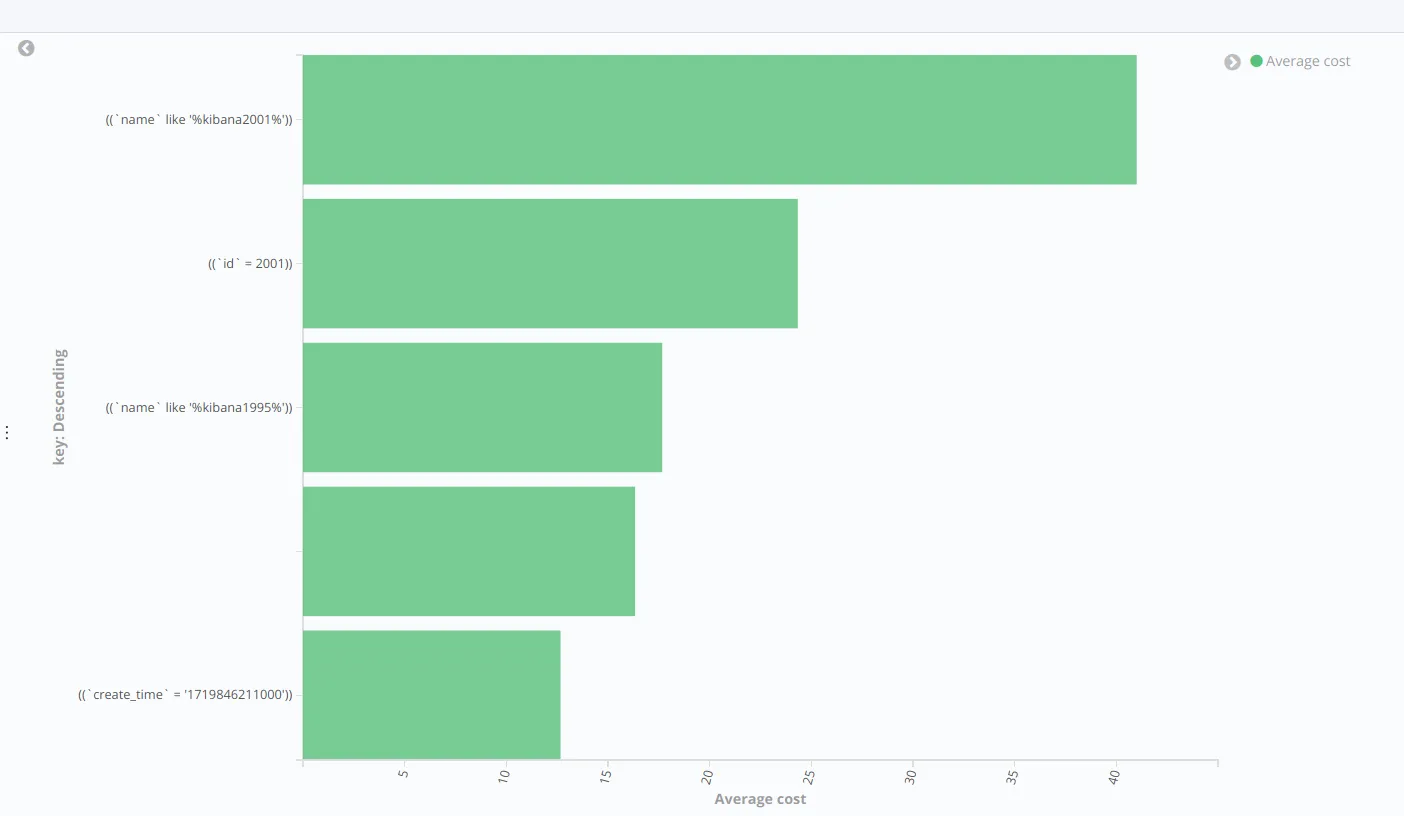
可以监控每个查询的详情,语法以及耗时索引为 proxy-monitor-*,cost 为查询耗时,key 为查询条件。这个配置刚刚上线的时候可以开启,用来观察那些查询耗时较长,不建议长时间开启
1 | |
当然还可以基于 kibana 的图表功能,做更直观的分析,如下图所示:
其他配置
- 更新ES配置
1
curl -v -X POST 'localhost:8080/config/updateEs?host=esHost&headers=key:value' - 更新 msearchThreadPoolCoreSize
1
curl -v -X POST 'localhost:8080/config/updateMsearchThreadPoolCoreSize?msearchThreadPoolCoreSize=4' - 获取配置接口
1
curl -v 'localhost:8080/config/all'
CKibana 高级功能
采样
Kibana 的图表大部分都是关注趋势,当命中结果集太大时候,消耗 ClickHouse 的资源也较多。CKibana 提供了采样功能,在数据集较大的时候,能够保障图表趋势跟实际的差不多,而且可以控制 ClickHouse 的资源使用。
当然采样的数据太少了,查看的趋势也会不太准确。
开启采样需要两步:
- 配置需要采样的表
1
curl -v -X POST 'localhost:8080/config/updateSampleIndexList?list=index1,index2' - 更新采样阈值,当命中结果集超过阈值时,会触发采样对应的 ClickHouse 的表需要按照 ClickHouse 的采样表创建 采样子句
1
curl -v -X POST 'localhost:8080/config/updateSampleCountMaxThreshold?sampleCountMaxThreshold=1500000'
采样规则:ckibana 源码

当设定的阈值低于查询结果总数量的 1% 时,Kibana 将自动调整显示的数据量,确保至少展示查询结果总数 1% 的数据。然而,如果配置的阈值超过了查询结果总数的 1%,那么 Kibana 将不再进行自动调整,而是直接按照配置的阈值来展示相应数量的数据。
时间 round + 缓存
当短时间内出现大量相似的查询时,为了减轻 ClickHouse 的负载并提高查询效率,可以考虑采用缓存机制。特别是当查询的条件在一段时间内可以视为相似时,通过缓存先前的查询结果(存在 Elasticsearch 中)可以显著提高性能。、
Q: 那么相似查询怎么可以用一份缓存呢?
A: 通过使用一个 round 功能,将查询的时间戳 round 到特定的时间间隔(如每20秒),使得相似的查询条件能够映射到相同的缓存键。这样,当新的查询到达时,系统首先检查缓存中是否存在与当前查询条件匹配的缓存项,如果存在则直接返回缓存结果,否则执行实际的数据库查询并将结果存入缓存以供后续使用。
假如 round 的值为 20s 则 key 映射示例如下:
- 查询时间在 0s-19s 映射成 0s-0s 即 0s
- 查询时间在 20s-39s 映射成 20s-20s 即 20s
- 查询时间从 01:50:15 到 05:52:47 , 则映射为从 01:50:00 到 05:52:40
简单来说就是相当于最多延迟了 20s 来查询数据
开启该功能需要两步:
- 开启缓存
1
curl -v -X POST 'localhost:8080/config/updateUseCache?useCache=true' - 配置时间 round (单位 ms)
1
curl -v -X POST 'localhost:8080/config/updateRoundAbleMinPeriod?roundAbleMinPeriod=20000'
参考链接
https://github.com/TongchengOpenSource/ckibana-docs
https://github.com/TongchengOpenSource/ckibana
https://clickhouse.com/docs/zh/sql-reference/statements/select/sample